Juju makes it easy to setup and monitor a Spark cluster with a few commands.
In this guide we will setup a new cluster and deploy a Spark job using this tool. According to the official definition, Juju is a service modelling tool that allows people to model, configure and deploy applications in the cloud. It also offers some monitoring capabilities as well as scaling.
The application we will deploy detects fraud in financial transactions as explained in this blog post.
We will be using Ubuntu 14.04.4 LTS on this guide. If you’re on another OS you can use VirtualBox to run Linux by following these instructions.
As a first step we need to install Juju (version 1.25 – latest stable):
Install Juju
sudo add-apt-repository ppa:juju/stable
sudo apt-get -y update
sudo apt-get -y install juju juju-local git make sshfs
sudo pip install bundletester
sudo apt-get -y install charm-tools
For Ubuntu versions <= 12.04 you may run into issues when trying to install juju-local and need to install LXC userspace tools and the MongoDB server as mentioned here.
Generate the config file
Each juju environment needs to know how to connect to your cloud / private infrastructure in which to deploy. By default Juju ships with AWS (default), HP Cloud, OpenStack, Azure, MaaS, Local and Manual providers. This information is stored in the environments.yaml file. To generate the template file run:
juju generate-config
Which generates the config file under ~/.juju/environments.yaml.
This will fill it out with template info. Edit it to reflect the cloud provider you want to use and the credentials juju will have to use.
We will use the local environment for demo purposes and will be deploying to lxc containers.
Bootstraping
In order to create the cloud environment that Juju will use to deploy to, we need to run the bootstrap command:
juju bootstrapThis will also install the public SSH key on the machine.
Running juju status will show information about the environment, the services deployed and the units. After running the bootstrap command there are no nodes or services deployed yet which should show something like this:
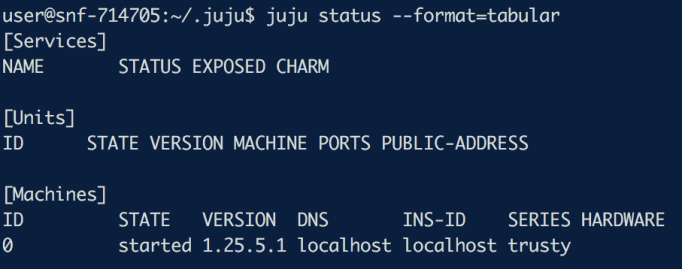
juju status –format=tabular
Keep the monitoring in the background using a watch:
watch juju status --format=tabularInstalling Spark
You can deploy Spark in either Standalone or High Availability (HA) mode.
juju deploy apache-sparkThis will first provision a VM and install the Spark charm on it. A Charm is a software component that contains all the instructions necessary to deploy and configure cloud-based services.
The above operation may take a few minutes. A more detailed view of what is going on int he background can be retrieved using:
juju debug-logOnce the operation has finished we shall see a master node in state Ready as shown below.
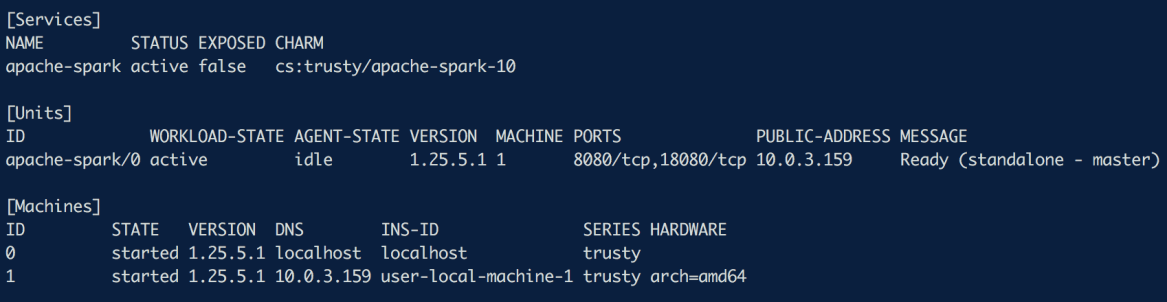
We can add new nodes to the spark cluster by running a simple juju add-unit command.
However, to enable high availability on a cluster of machines it is essential we install Zookeeper, the distributed resource coordination service that Spark uses.
To do so, we need to run
juju deploy apache-zookeeper…which will spawn a new node (or an lxc-container in case we run it locally), download zookeeper and run it. It will be ready to use when the status is shown as Ready at the juju status command. Although a ZooKeeper node is up and running, juju status will show as Ready (1 zk units: less than 3 is suboptimal). This is because Zookeeper requires at least 3 or more (odd) number of nodes to be fully functional. Given that ZK functionality is based on agreement between distributed nodes, the majority of votes – and therefore the truth – can be achieved with 3 or more nodes. This is because if one machine fails in a cluster of 2 machines, the remaining machine does not constitute a majority. With 3 nodes, we can tolerate 1 node failure and still operate with the majority of two nodes.
In order to fix this, let’s add 2 more ZK nodes by running:
juju add-unit -n 2 apache-zookeeperand wait until they are in state ‘Ready’ again.
Now that ZK is up and running we can add new nodes to our Spark cluster by running:
juju add-unit -n 2 apache-sparkNotice that we have not connected Spark with Zookeeper yet. To do so, we need to let juju know about the relation:
juju add-relation apache-zookeeper apache-spark
You can see that the spark cluster is now in HA (High Availability) mode. It is not clear who the master node is but we can retrieve this information by logging into one of the ZK nodes and asking for it.
juju ssh apache-zookeeper/0
zkCli.sh
get /spark/master_statusSo the spark master is 10.0.3.159 ! In order to verify our cluster works correctly we need to submit a test job. The easiest way to do this is to ssh to one of the spark nodes and run:
spark-submit --class org.apache.spark.examples.SparkPi --master spark://10.0.3.159:7077 /usr/lib/spark/lib/spark-examples*.jar 10By looking at the /var/log/spark/spark.log on each of the three nodes we can see that the job has been submitted successfully and is running. After a few seconds Pi should be ……… 3.14.
Running Anomaly Detection on cluster
First let’s make the training data available on each machine by running:
for i in $(seq 0 1 2); do
juju ssh apache-spark/$i "
mkdir -p /home/ubuntu/src/test/resources
cd /home/ubuntu/src/test/resources
wget https://raw.githubusercontent.com/mvogiatzis/spark-anomaly-detection/master/src/test/resources/training.csv
wget https://raw.githubusercontent.com/mvogiatzis/spark-anomaly-detection/master/src/test/resources/cross_val.csv
"
done
Also make the jar available by uploading it on the juju machine and scping it to all three nodes:
juju scp anomaly-detection_2.10-1.0.jar apache-spark/
Time to submit our application. Logging into one of the nodes that can talk to the master node, a Spark application can be submitted to the cluster as usual:
spark-submit --class MainRun --master spark://10.0.3.159:7077 --total-executor-cores 8 target/scala-2.10/anomaly-detection_2.10-1.0.jar
Looking at the logs /var/log/spark/, we can see the same results/outliers that were computed at our standalone server:

Conclusions
We saw how Juju makes the Spark setup and deployment straightforward and easy to reason about. It took a few steps to setup a Spark cluster and deploy the anomaly detection application. Details about how the fraud-detection app works can be found here.
I’d like to thank the Canonical big data team for letting me run my experiments using their powerful resources. They are doing a great job and are now also working on integrating juju charms within the Apache BigTop project which provides management, maintenance, testing and virtualization for various big data projects such as Hadoop and Spark.
Stay connected ! You can subscribe to the blog using your e-mail.
