The code is open-source and available on Github.
– “Which pages are getting an unusual hit in the last 30 minutes?”
– “Which categories of items are now hot?”
We want to know which items exceed a certain frequency and identify events and patterns. Answers to such questions in real-time over a continuous data stream is not an easy task when serving millions of hits due to the following challenges:
- Single Pass
- Limited memory
- Volume of data in real-time
The above impose a smart counting algorithm. Data stream mining to identify events & patterns can be performed by applying the following algorithms: Lossy Counting and Sticky Sampling. Below I will demonstrate how these problems can be solved efficiently.
Lossy Counting
Step 1: Divide the incoming data stream into windows.
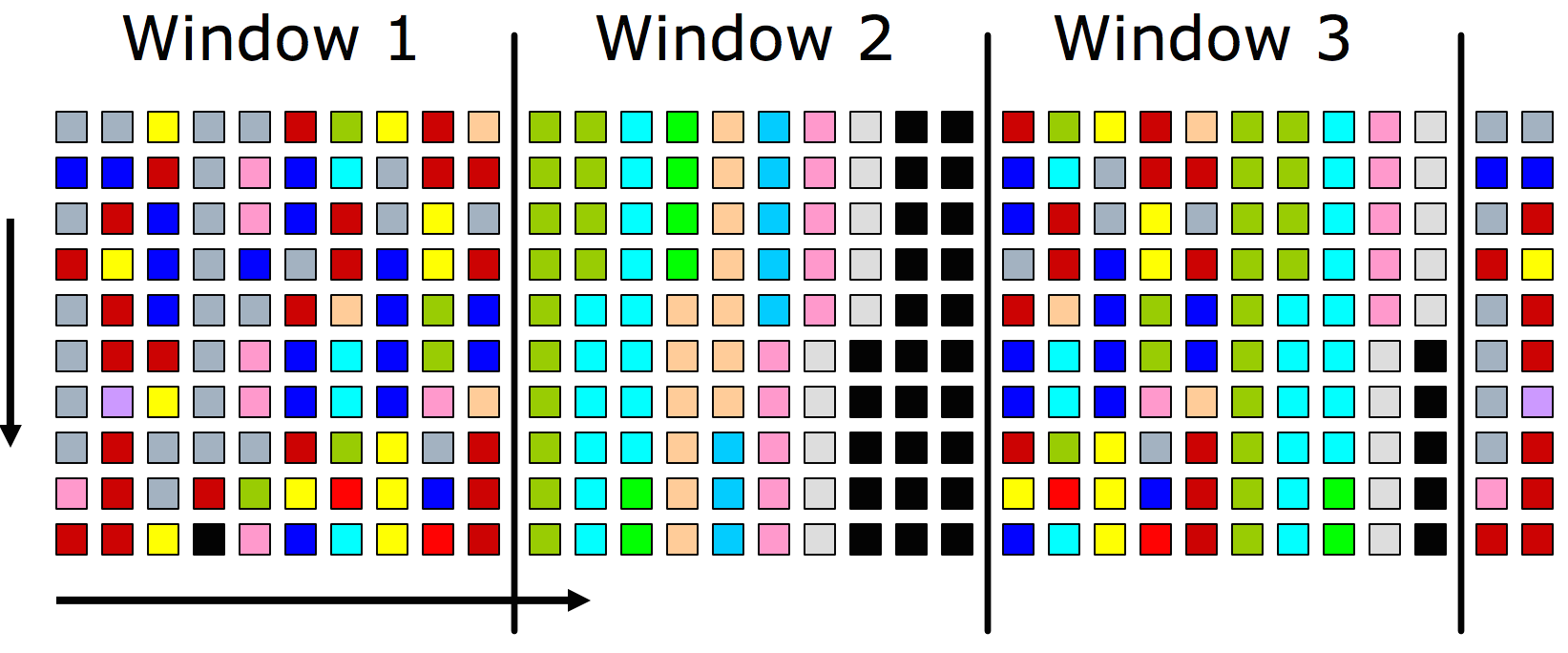
Split input stream into windows
Step 2: Increment the frequency count of each item according to the new window values. After each window, decrement all counters by 1.
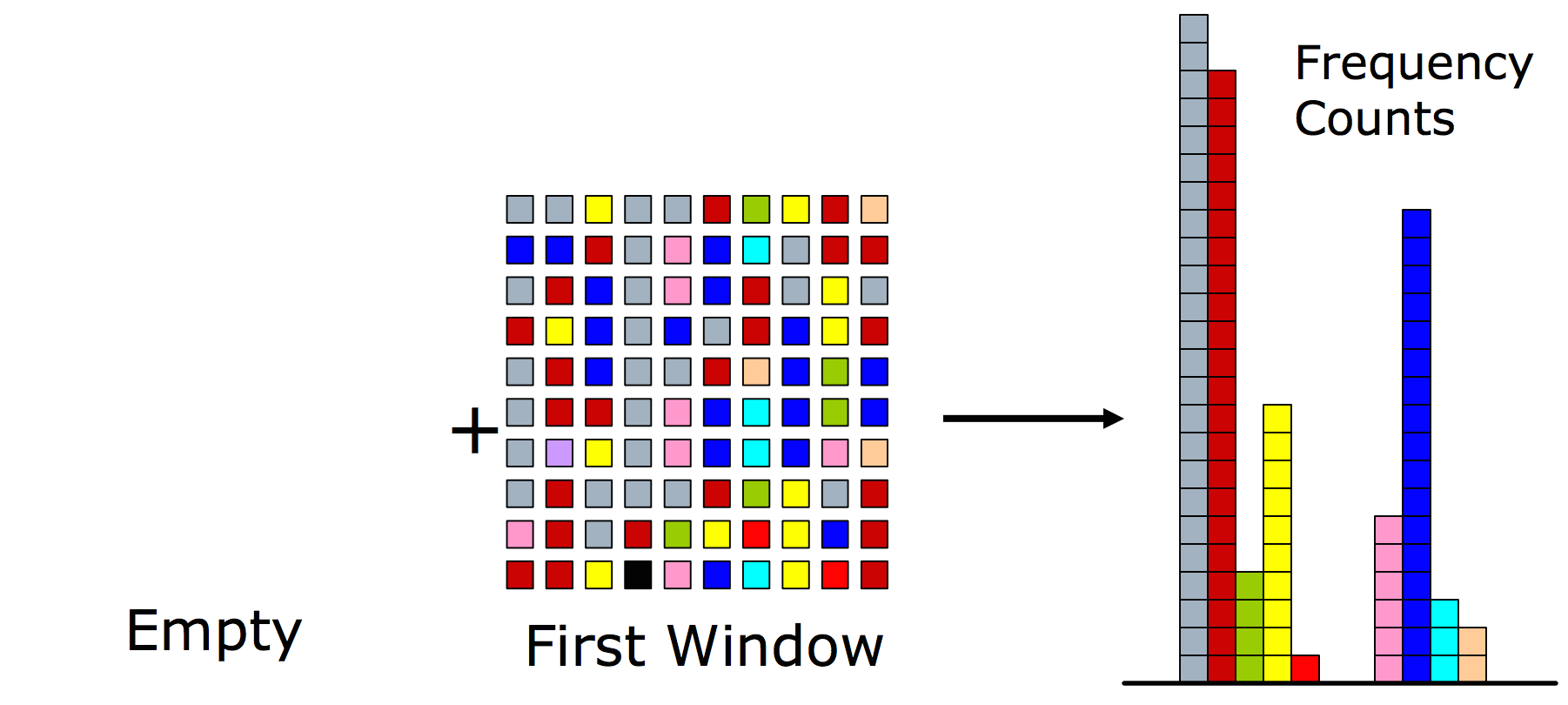
Increment frequency counts – At window boundary adjust counts
Step 3: Repeat – Update counters and after each window, decrement all counters by 1.

Update counters and at window boundary decrement all items by 1
Output
The most frequently viewed items “survive”. Given a frequency threshold f, a frequency error e, and total number of elements N, the output can be expressed as follows: Elements with count exceeding fN – eN.
Worst case we need (1/e) * log (eN) counters.
For example, we may want to print the Facebook pages of people who get hit more than 20%, with an error threshold of 2% (rule of thumb: error = 10% of frequency threshold, see paper).
For frequency f = 20%, e = 2%, all elements with true frequency exceeding f = 20% will be output – there are no false negatives. But we undercount. The output frequency of an element can be less than its true frequency by at most 2%. False positives could appear with frequency between 18% – 20%. Last, no element with frequency less than 18% will be output.
Given window of size 1/e, the following guarantees hold:
- Frequencies are underestimated by at most e*N
- No false negatives
- False positives have true frequency of at least f*N – e*N
The Scala code along with a demonstrable example is available here.
Sticky Sampling
This is another technique for counting but probabilistic. Here the space consumption is independent of the length of the stream (N).

The user defines the frequency threshold (f), the error (e) but also the probability of failure (δ).
The logic is the following: For each incoming item, if an entry exists we increase its frequency. Otherwise we may select the item based on a probability 1/r. This is called sampling. We gradually increase the sampling rate (starting at r=1) as more elements are processed. Upon a sampling rate change, we scan all existing entries. For each entry, we toss an unbiased coin and we decrease the item’s frequency for each unsuccessful toss, until the coin toss becomes successful or the frequency becomes 0 at which we release the entry.
The sampling rate is adjusted according to the following formula: t = (1/e) * log (1 / (f * δ) )
The first t elements are sampled at rate r=1, the next 2t elements at rate r=2, the next 4t at rate r=4 etc.
Output
Same as lossy counting: Given a frequency threshold f, a frequency error e, and total number of elements N, the output can be expressed as follows: Elements with count exceeding fN – eN.
Number of counters expected (probabilistically): (2/e) * log(1/ (f*δ))
It’s worth noting that the number of counters here is independent of N, the length of the stream.
The same guarantees as lossy counting apply here:
- Frequencies are underestimated by at most e*N
- No false negatives
- False positives have true frequency of at least f*N – e*N
A demo example can be found here.
End of Story
- Lossy counting is more accurate but Sticky Sampling requires constant space. Lossy Counting space requirements increase logarithmically with the length of the stream N.
- Sticky sampling remembers every unique element that gets sampled, whereas Lossy Counting chops off low frequency elements quickly leaving only the high frequency ones.
- Sticky sampling can support infinite streams while keeping the same error guarantees as Lossy Counting.
Future Work
Both techniques can be implemented in a distributed fashion in order to benefit from the processing power and the fault tolerance these can provide. Spark or Storm are suitable candidates for such streaming algorithms, with the challenge being having to keep and update a global state for total items processed and rate.
Resources:

Filter count(matched-items)
https://en.wikipedia.org/wiki/Alpha_beta_filter
or, if you want to get fancy:
https://en.wikipedia.org/wiki/Kalman_filter
[…] Frequency Counting Algorithms over Data Streams […]